Być lekarzem być lekarzem
De testimonio: o wykorzystywaniu dowodów naukowych w podejmowaniu decyzji lekarskich
Michael Rawlins, MD, FRCP, FFPM, FMedSci
W SKRÓCIE
Decyzje o podejmowaniu działań terapeutycznych, zarówno wobec poszczególnych chorych, jak i w całym systemie opieki zdrowotnej, powinny się opierać na całokształcie dostępnych dowodów naukowych. Mniemanie, że dowody można zhierarchizować według ich wiarygodności czy użyteczności, jest złudne. Podejmujący decyzję muszą raczej osądzić, czy (i kiedy) dowód z badania doświadczalnego lub obserwacyjnego należy uwzględnić w danej sytuacji.
William Harvey (1578-1657) należał do XVII-wiecznych filozofów przyrody, którzy przestali opierać rozumienie świata na autorytetach Arystotelesa, Platona czy Galena. Jak sam Harvey jednak zauważył: „podstawą jest uzyskiwanie wiedzy od innych, bez konieczności samodzielnego badania zagadnienia, zwłaszcza że księga natury stoi otworem i łatwo [po upowszechnieniu druku – przyp.red.] wymieniać się zdobytą wiedzą”.1 Filozofowie przyrody tamtych czasów, chociaż zjednoczeni w dziele zgłębiania księgi natury, zawzięcie spierali się jednak, w jaki sposób należy to czynić. Trzy i pół wieku później dyskusja o istocie nauki i metodach naukowych toczy się nadal i w sposób szczególny dotyczy zależności między metodami indukcyjnymi a dedukcyjnymi.2
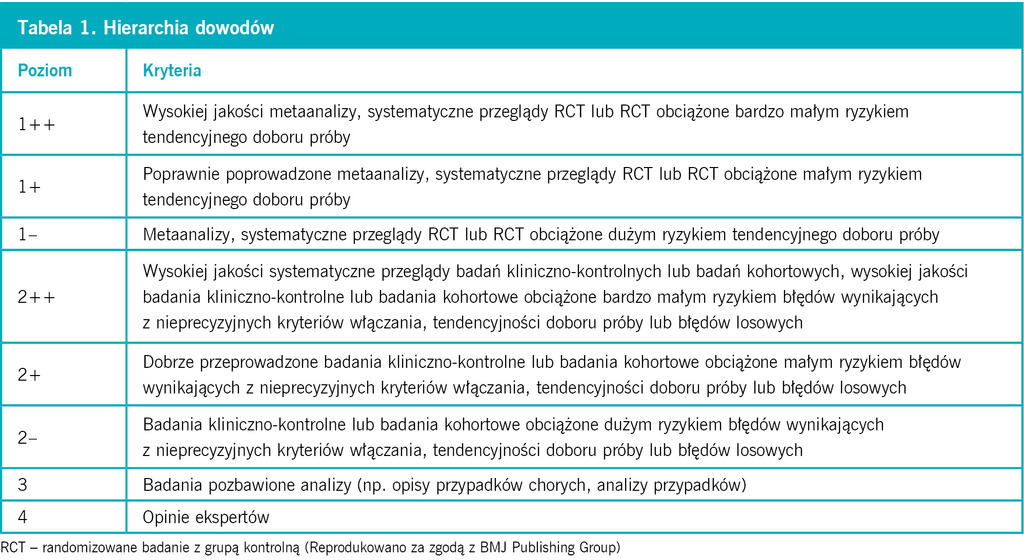
Tabela 1. Hierarchia dowodów
Nigdy dotąd równie stanowczo, a czasem zawzięcie, nie przekonywano, że dowody naukowe muszą potwierdzać przydatność działań terapeutycznych. Stało się to szczególnie widoczne w ciągu ostatnich 30 lat, kiedy tworzono rozmaite reguły, poziomy i hierarchie dowodów. Typowy przykład przedstawiono w tabeli 1.
Dowód naukowy spełnia obecnie tylko jeden cel. Stanowi podstawę do podjęcia świadomej decyzji o właściwym zastosowaniu działań terapeutycznych w praktyce lekarskiej. Decyzje te podejmuje się na różnych szczeblach, ale ich skutki zawsze mają zasadnicze znaczenie dla chorych, ich rodzin i społeczeństwa. Decydenci rozstrzygają o zasadności stosowania danej metody leczenia, którą następnie proponuje się konkretnym pacjentom, decydują o konieczności zaopatrzenia szpitala w pewne produkty i pełni emocji oceniają, czy dany sposób leczenia jest wystarczająco bezpieczny i skuteczny, a także zasadny ekonomicznie, by wykorzystywać go w całym systemie opieki zdrowotnej. Skutki błędnych decyzji mogą być tragiczne.
W drabinach hierarchii dowodów naukowych badania z grupą kontrolną i randomizacją (RCT – randomized controlled trial) umieszcza się na samym szczycie, pozostawiając u ich podnóża różne formy badań obserwacyjnych. Hierarchie te dają poczucie siły ocenianego dowodu. Na podstawie tak postrzeganej siły opracowujący wytyczne nadają następnie rangę określonym rekomendacjom terapeutycznym.
Pogląd, że dowód naukowy można niezawodnie umiejscowić w hierarchii, jest jednak złudny. Stawianie RCT na tak wysokim piedestale bywa kłopotliwe, bowiem każda metoda badawcza ma zarówno wady, jak i zalety.4 Badania obserwacyjne mają swoje ograniczenia, ale nie są pozbawione wartości. Decydenci muszą ocenić wszystkie dostępne dowody, niezależnie od tego, czy pochodzą one z RCT, czy z badań obserwacyjnych, a także poznać mocne i słabe strony każdego z nich. Dopiero wtedy mogą wyciągnąć wiarygodne wnioski. Nie ma nic zawstydzającego w tym, że zanim jakiś dowód zostanie uwzględniony w analizie, należy go ocenić pod kątem adekwatności do sytuacji, w jakiej się go wykorzystuje. Z drugiej strony, osobisty osąd jest nieodłączną składową większości aspektów procesu podejmowania decyzji.5
Badania z grupą kontrolną i randomizacją
Wprowadzenie RCT w połowie XX wieku miało głęboki wpływ na praktykę kliniczną, a ich zasadnicze założenia zostały dokładnie opisane.4,6,7 Polegają one na porównaniu wyników dwóch (lub większej liczby) metod zastosowanych w tym samym czasie u wyodrębnionych losowo grup pacjentów.
Prawidłowo przeprowadzone i przeanalizowane RCT z podwójnie ślepą próbą bez wątpienia wzbudza zaufanie, co do wiarygodności wyników oraz korzyści płynących z zastosowania danej interwencji,6,8 zwłaszcza jeśli rezultaty te powtarzają się w kolejnych badaniach. Dlatego RCT często nazywa się złotym standardem w potwierdzaniu (lub negowaniu) korzyści wynikających z poszczególnych działań medycznych. Metodę tę cechują jednak ważne ograniczenia, wśród których szczególny problem sprawiają cztery: hipoteza zerowa, prawdopodobieństwo, uogólnianie wyników oraz zależność od nakładów.
Hipoteza zerowa
Analiza RCT tradycyjnie opiera się na hipotezie zerowej zakładającej, że porównywane metody leczenia nie różnią się między sobą. Testuje się ją, szacując prawdopodobieństwo (częstość) uzyskiwania wyników skrajnych, przemawiających za słusznością tej hipotezy. Jeśli prawdopodobieństwo jest mniejsze niż pewna arbitralna wartość – zwykle mniejsze niż 1 na 20 (tj. p<0,05) – hipotezę zerową odrzuca się. Jest to najczęstsza metoda projektowania i analizy RCT, której niewątpliwymi zaletami są: łatwość obliczeń statystycznych, powszechna akceptacja metodologii oraz ustalone kryteria istotności statystycznej.
Hipoteza zerowa może być jednak niewłaściwa, choćby w przypadku, gdy we wcześniejszych badaniach wykazano już korzyści płynące z zastosowania danej metody leczenia. Zdarza się tak podczas opracowywania nowego leku, gdy wyniki wstępnych badań II fazy, ocenia się w badaniach III fazy na większych grupach chorych. Wówczas, opieranie analizy wyników badań III fazy na hipotezie zerowej staje się niezgodne z intuicją. Obserwacje przeprowadzone w ciągu ostatnich 10 lat ujawniają, że w 73% RCT opublikowanych w liczących się czasopismach nie próbowano zestawić uzyskanych wyników z osiągniętymi podczas wcześniejszych badań.9
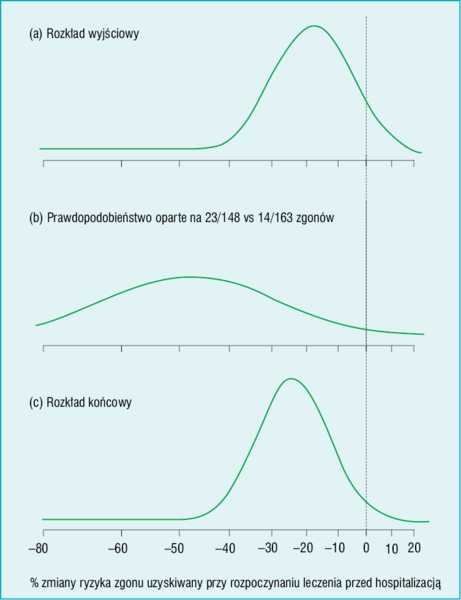
Rycina 1. Ponowna analiza wyników badania GREAT, przeprowadzona metodą Bayesa, przedstawiająca zmianę (zmniejszenie) umieralności wśród chorych, którym leczenie trombolityczne zastosowano przed przyjęciem do szpitala w porównaniu z podaniem tego leczenia w szpitalu
Hipoteza zerowa sprawia jeszcze większy kłopot w badaniach próbujących wykazać, że wyniki leczenia jednej z grup są takie same (ekwiwalentne), nie gorsze (non-inferiority study) lub wykazują założoną wcześniej różnicę (futility studies) w porównaniu z wynikami uzyskanymi w drugiej grupie.10 Wszystkie takie badania wymagają założenia z góry różnicy między badanymi metodami leczenia, którą można będzie uznać za znaczącą. Metodologia hipotezy zerowej w rzeczywistości może być zgodna z dedukcyjnym podejściem do nauki, jak bowiem stwierdził Rothman: „przyjmowanie uniwersalnej hipotezy zerowej jest w istocie zawieszeniem wiary w świat rzeczywisty, a zatem kwestionowaniem podstaw empiryzmu”.11
Prawdopodobieństwo
Wartość p
W najczęściej stosowanym ujęciu, jeśli wartość p (znamienności statystycznej) jest wystarczająco mała, to hipoteza zerowa jest fałszywa, a jeśli nie, to zdarzenia występowały zbyt rzadko, by hipotezę zerową odrzucić. Dla rozróżnienia tych dwóch możliwości powszechnie przyjęto, iż prawdopodobieństwo, że hipoteza zerowa jest prawdziwa, powinno być mniejsze niż 5% (tj. p<0,05). Jeśli wartość p jest większa lub mniejsza niż 0,05, odpowiednio odrzuca to lub potwierdza słuszność hipotezy zerowej. Niektórych, choć nie wszystkich, problemów związanych z wartością p można uniknąć, wyrażając wyniki w przedziałach ufności, które określają stopień niepewności lub braku dokładności wyników. Niemniej jednak wartość p i przedział ufności są ściśle ze sobą powiązane.